本文最后更新于:11 天前
ROIS夏令营 WEEK1 MySQL学习记录 解决mysql任意密码登录的问题:
1 2 3 update user set plugin="mysql_native_password";
docker拉mysql:
1 2 docker pull mysql:latest
1 docker run -d --name =mysql-server -p 3306:3306 -v mysql-data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD =your_password mysql
7.9 配置环境参考docker-note中文章
默认在3306端口运行MySQL服务。
数据库管理系统:
用来管理数据库中数据的,对数据增删查改。常见:MySQL、DB2、Oracle等。
执行MySQL命令时注意以分号结尾,不见分号不执行
SQL语句不区分大小写
常用命令:
1 2 3 4 5 show databases;#查看有哪些数据库
表(table ):
行(row)
列(字段)(column )
SQL语句:
DQL:数据查询语言(带SELECT)
1 2 3 4 5 6 7 8 9 10 11 12 13 SELECT <字段名> FROM <表名>#如果查询多个字段字段间用逗号隔开,查询全部用*或者一个一个字段敲进去,星号效率低,实际开发不建议使用
DML:数据操作语言(对表当中数据增删改)
1 2 3 INSERT#增
DDL:数据定义语言(CREATE、DROP、ALTER,主要操作表结构而不是修改数据,如删掉某列,增加新的一个字段、创建、删除表)
1 2 3 4 CREATE#新建
TCL:事务控制语言
1 2 COMMIT#事务提交
DCL:数据控制语言
1 2 3 #eg:
下面用上面学到操作的先制作一个测试用数据库练练手
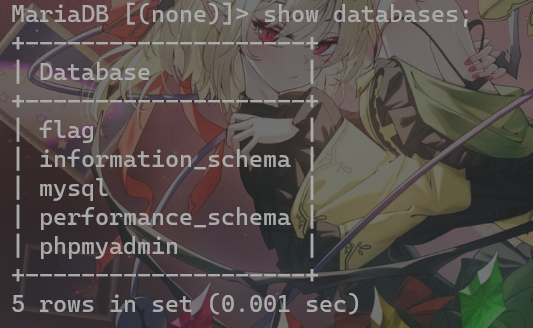
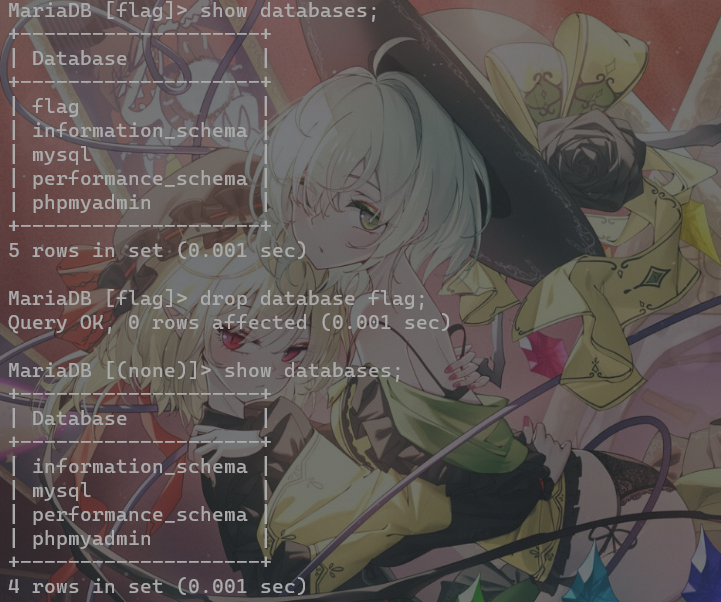
先看一下有哪些数据库 show databases;,之前复现题目环境时创建了个flag数据库,正好可以试下删除数据库的操作
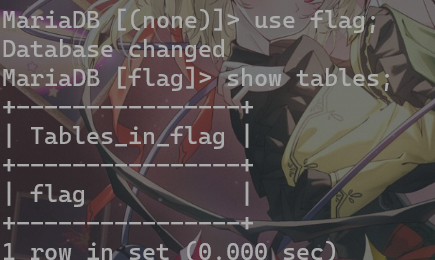
use flag;进入该数据库,show tables;查看数据库内所有表
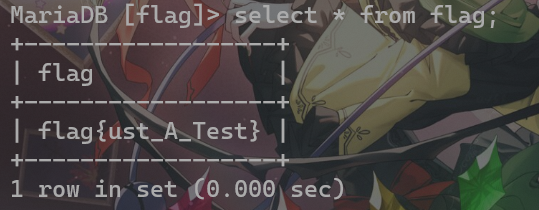
浅查一下
查完,删表跑路(bushi
可以看到我们的test数据库内只有一个flag表,下面删除该表drop table flag;
使用drop table <表名>;删表,这时候我们再查数据库中的表名,已经是空的了,那一不做二不休,试一下删数据库drop database flag;
可以看到flag数据库已经被删除了。
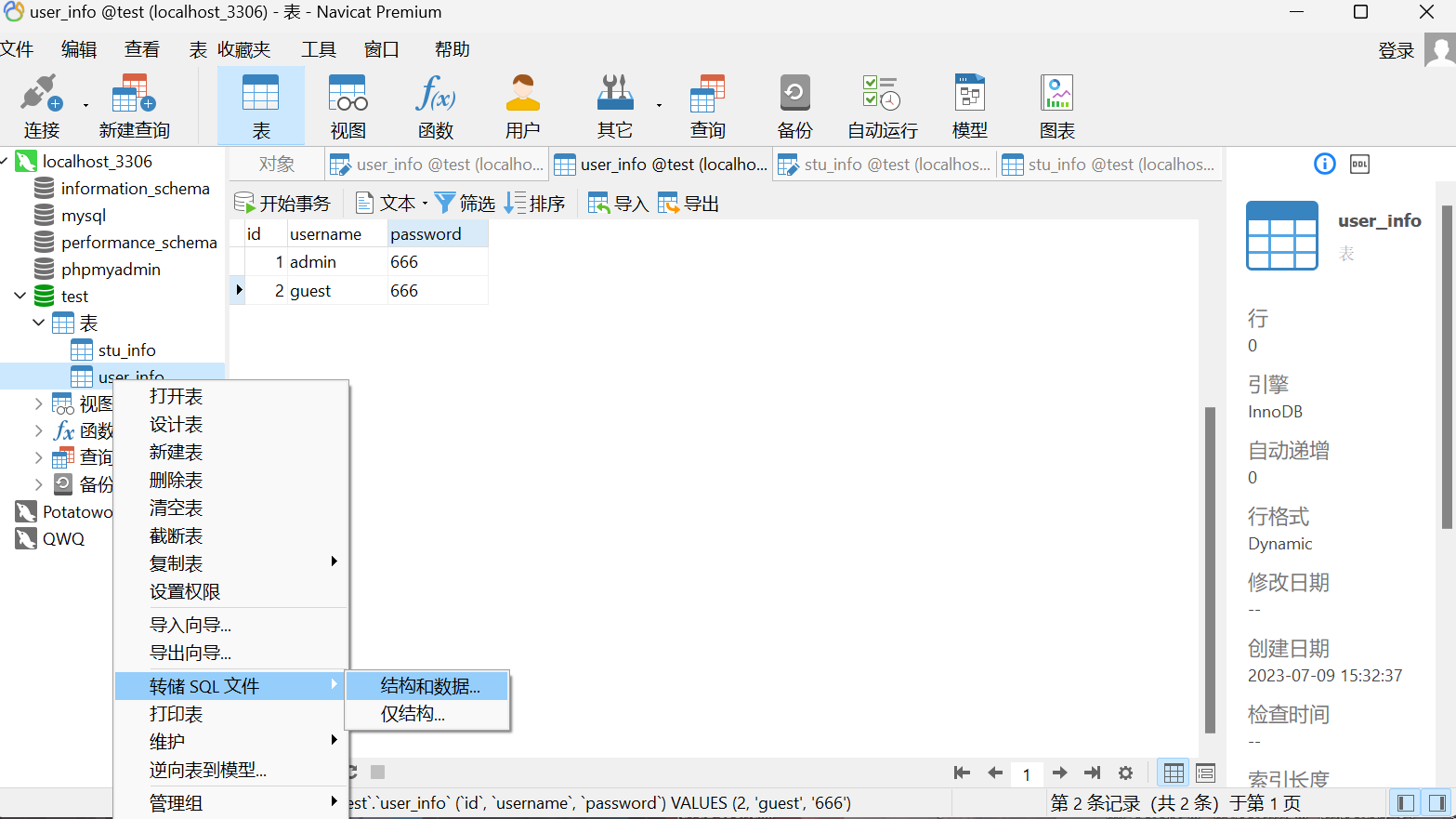
这里先开navicat可视化快速创个数据库然后导出,一会尝试从文件导入
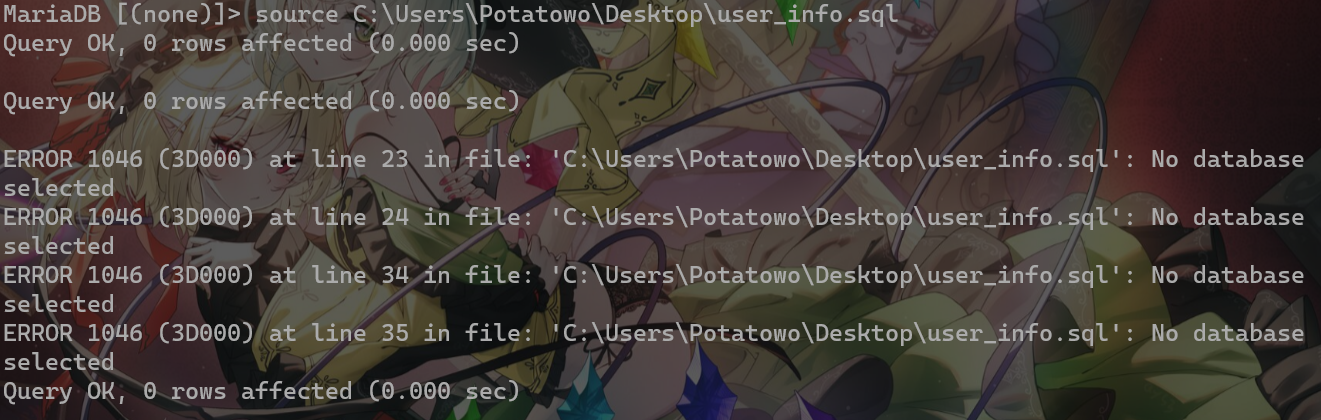
导入文件的时候踩了个坑(其实还有个坑,这个坑也是几乎所有编程语言共有的,养成良好习惯从我做起(,路径中憋整中文)
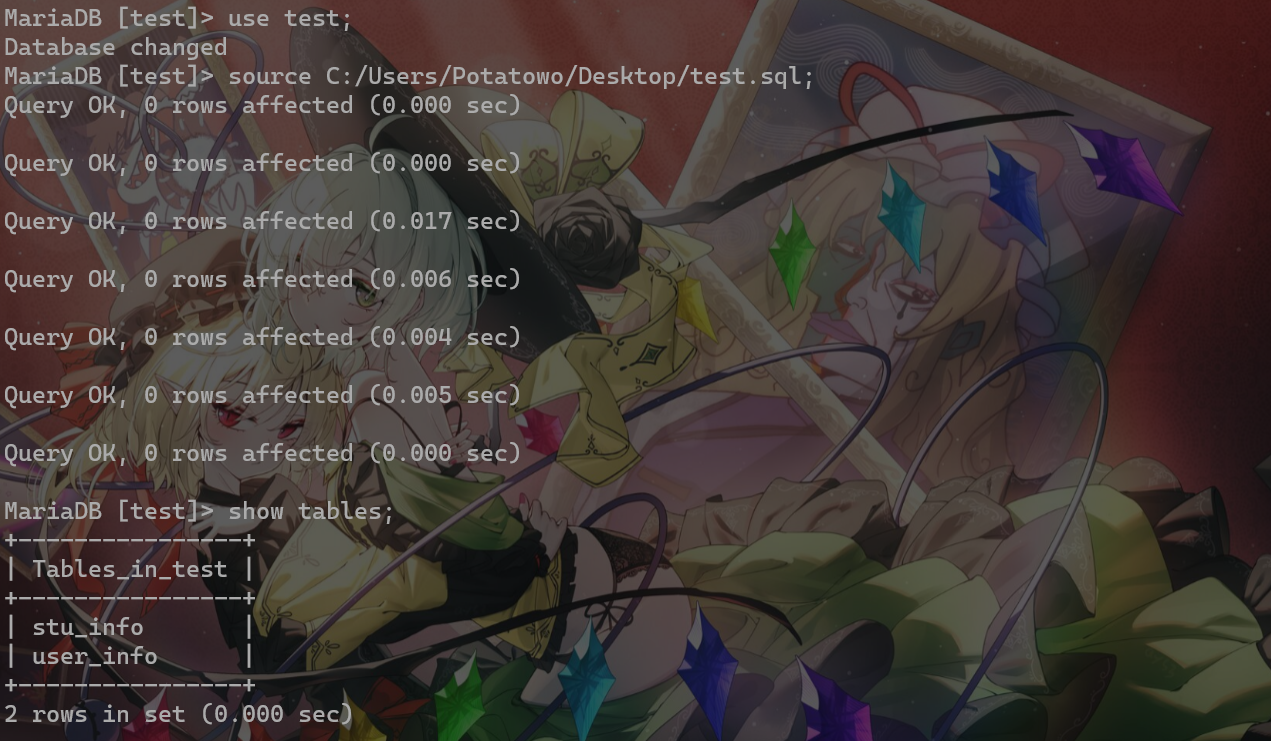
使用命令source <file_url>;导入sql文件(意外发现其实source命令也可以不需要分号,但是养成好习惯,都加)
要先选中一个数据库再导入
如图所示便导入成功:
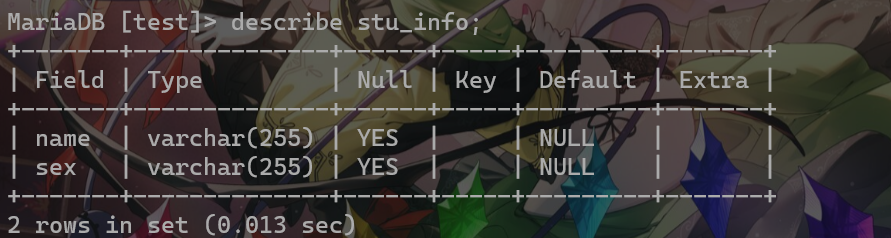
查看表结构,不看数据,使用describe <表名>;命令(或者desc <表名>也可)
然后感觉自己创的表太草率了,找了个更好的数据库导入了(
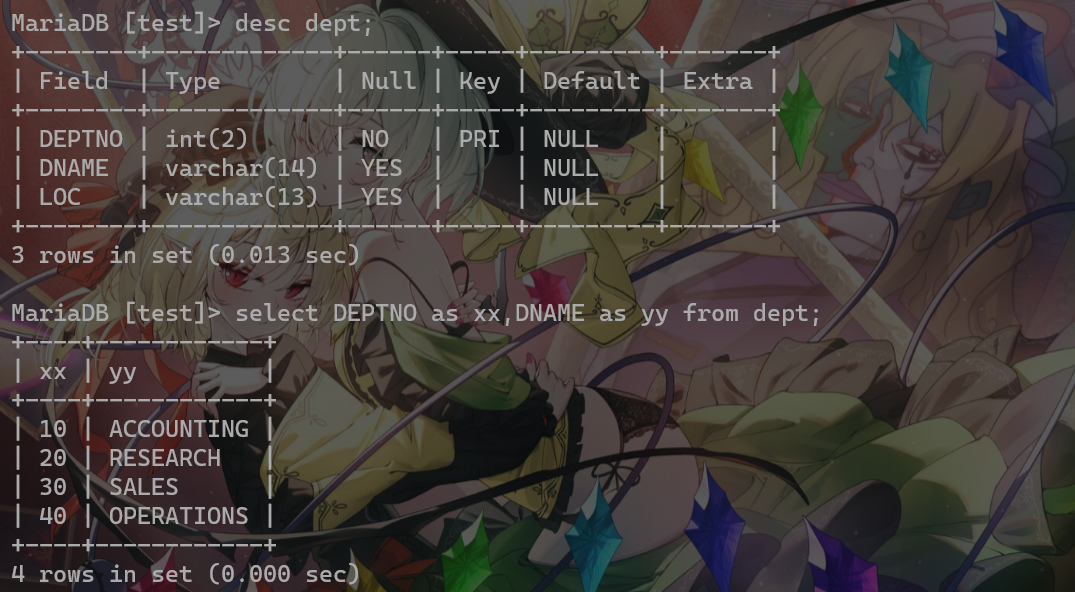
下面进行desc查表结构以及使用as关键字对查询字段起别名(注意as只对一个字段生效)(as可省,但是注意别名和真名间不要有逗号):
起别名不对原表字段名造成影响
SELECT语句永远无法进行修改操作
在所有数据库中,字符串是用单引号括起来的,双引号在Oracle中无法使用但是在MySQL中可以,例别名中有空格别名用单引号括起来
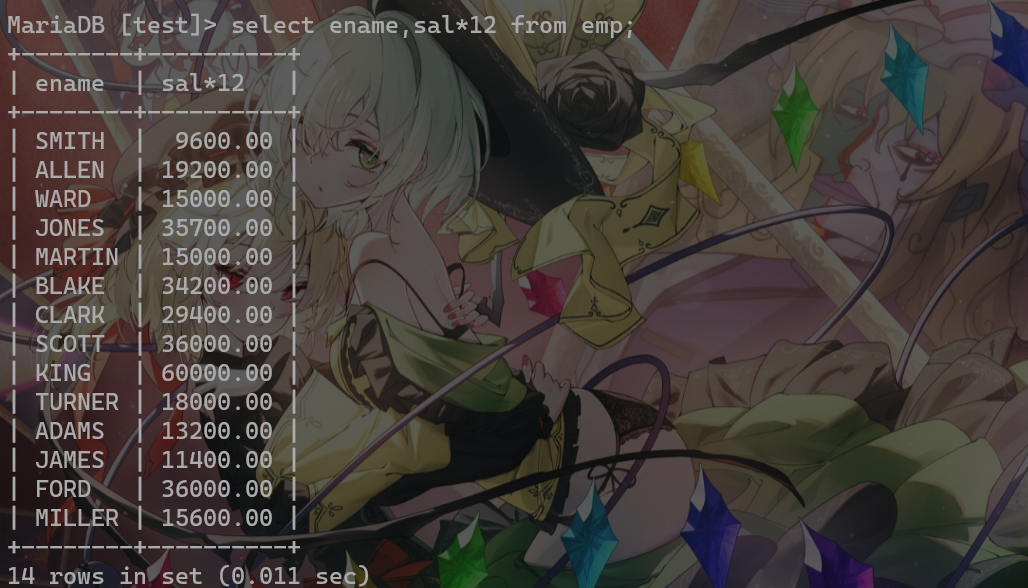
字段可以使用数学表达式:
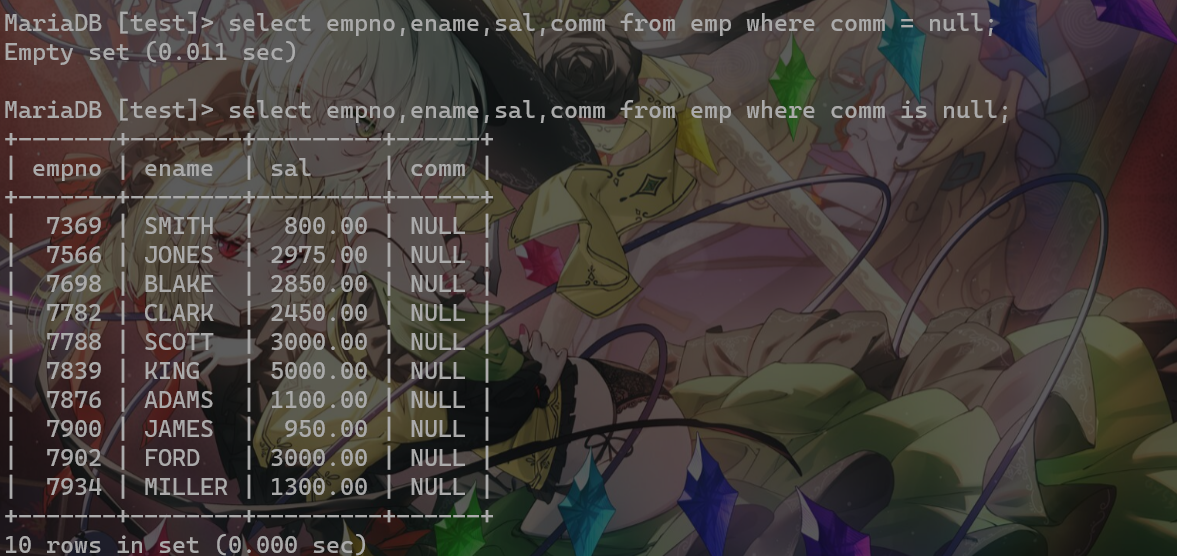
7.10 MySQL中NULL不能用=衡量,只能用is/is not,因为数据库中的NULL是表示该位置为空,而不是一个值,是一个属性
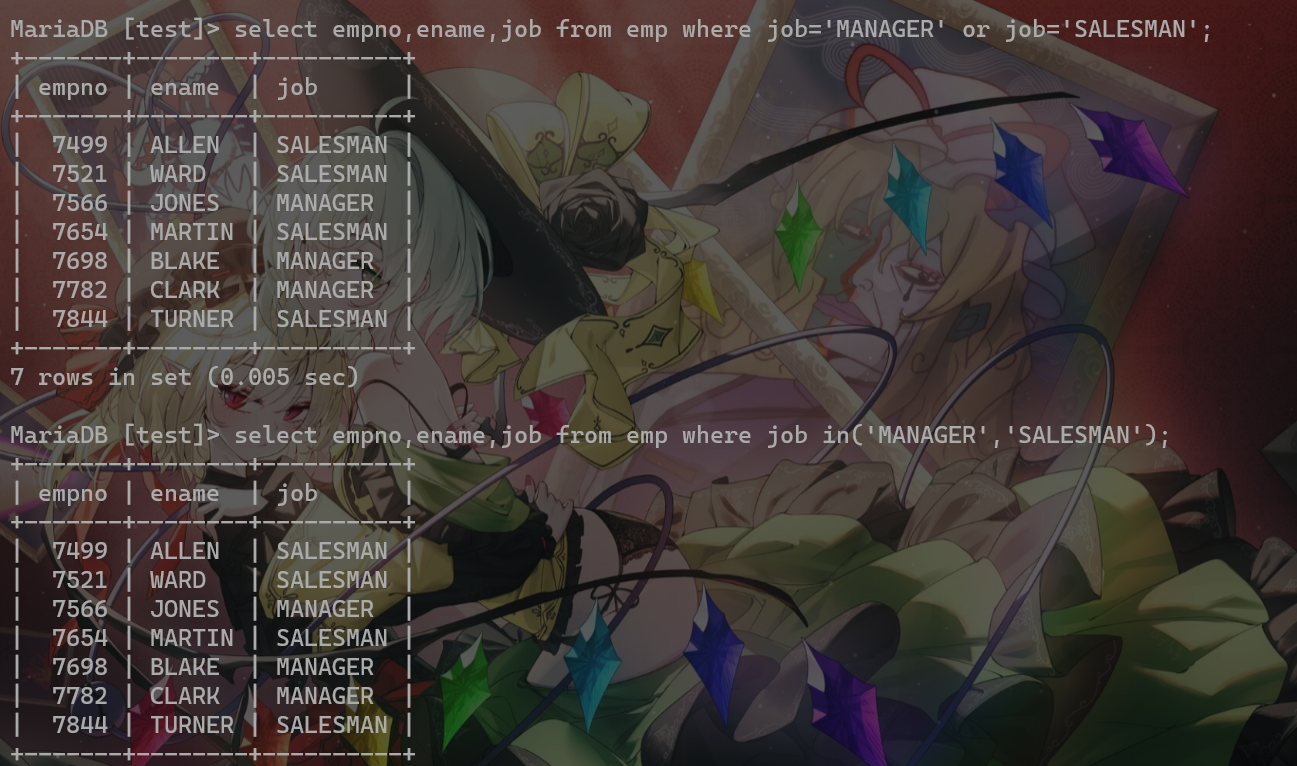
IN关键字(等价于多个or),取反用not in():
like(模糊查询,sql注入会使用到):
‘%’匹配任意个字符(可理解为正则表达式.*?);
‘_’一个下划线只匹配一个字符(可以理解为正则表达式的.);
eg:
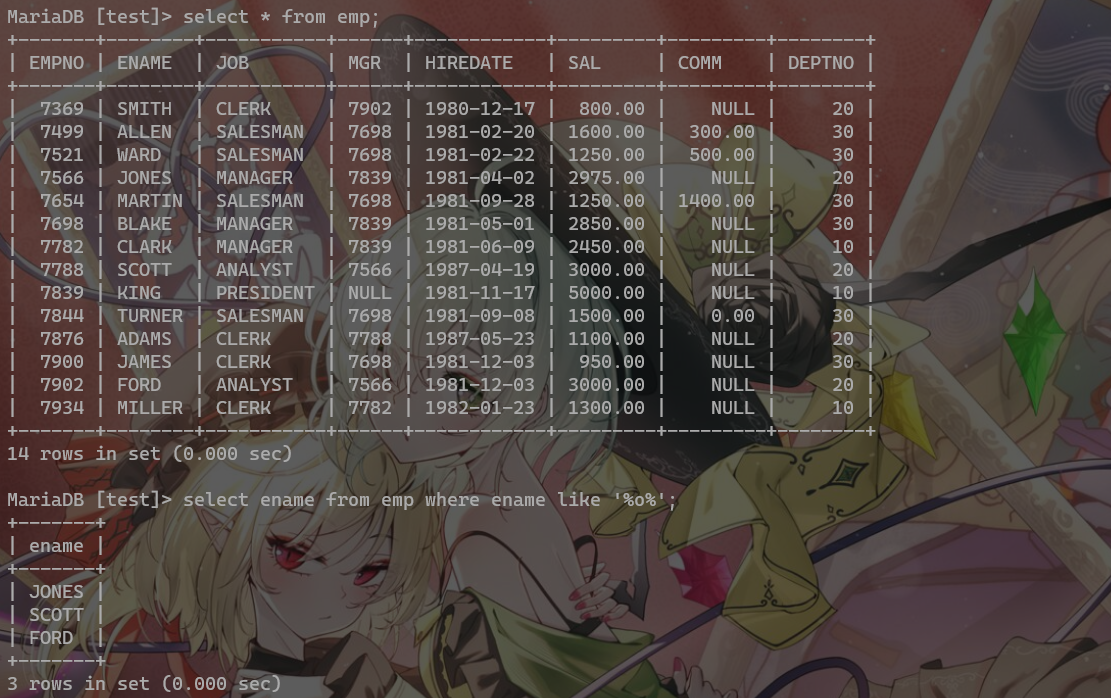
查询名字里含有字符’o’的:
1 select ename from emp where ename like '%o%';
OUTPUT:
eg:
以T结尾
1 select ename from emp where ename like '%T';
以K开始
1 select ename from emp where ename like 'K%';
找出第二个字母是A的
1 select ename from emp where ename like '_A%';
找出含下划线的
1 select ename from emp where ename like '%\_%';#使用转义字符'\'
order by排序:
order by sal默认升序,指定降序order by sal desc(descend),指定升序order by sal asc(ascend)
多字段排序:
1 2 #查询员工名字和薪资,要求按照薪资升序,薪资相同按照名字升序
根据字段位置排序(sql注入常用)
1 select ename,sal from emp order by 2;#2表示第二列
数据处理函数:
1 2 3 4 5 6 7 8 9 10 11 12 Lower()#转换小写
substr()起始下标从1开始而不是0!
找出员工名字第一个字母是A的员工信息?
两种方法:
select ename from emp where ename like 'A%';select ename from emp where substr(ename,1,1)='A';
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 select ename,sal + comm as salcomm from emp;#数据库中有null参与的数据运算结果都为null
ifnull()的用途:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 select ename,sal + ifnull(comm,0) as salcomm from emp;
case...when...then...when...then...else...end:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #eg:当员工工作岗位是MANAGER时工资上调10%,当员工工作岗位是SALESMAN时工资上调15%,其他正常
7.11 分组函数:
输入多行,输出一行
1 2 3 4 5 count()#计数,count(*)表示统计所有行数,count(具体字段)代表统计该字段下不为null的
分组函数自动忽略null,不需要对null进行处理
分组函数在使用时必须分组,没分组默认整张表是一组
分组函数不能直接使用在where语句:
1 2 3 4 5 6 7 8 select ename,sal from emp where sal > min(sal);#表面上没问题
分组查询:(SQL注入常用)
1 2 3 4 5 6 7 8 9 10 11 12 #找出每个工作岗位的工资和?
在一条SELECT语句中如果有GROUP BY,SELECT后面只能跟参加分组的字段和分组函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 select ename,sal,deptno from emp;#先查一下表,可以看到10部门中最高工资是KING,20部门中最高工资是FORD和SCOTT,30部门中最高工资是BLAKE
按多个字段联合分组:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #找出每个部门,不同工作岗位的最高薪资
如果想对分完组之后的数据进一步过滤,不要用WHERE(参考上面的内容),而应该用HAVING子句
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #eg:找出每个部门最高薪资,要求显示最高薪资大于3000的
但是上述语句效率相对比较较低,实际上可以这样考虑:
先将薪资大于3000的用WHERE过滤了,不大于3000的就不进行分组了
1 2 3 4 5 6 select deptno,max(sal) from emp where sal > 3000 group by deptno;
where和having优先选择where,where没办法的再选择having(比如对每个部门平均薪资进行限制的)
distinct关键字:
把查询结果去除重复记录,注:原表数据不会被修改,只是查询结果去重
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 select job from emp;
distinct只能出现在所有字段的最前方,如果后面有多个字段,则联合去重:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 select job,deptno from emp;
连接查询:
笛卡尔积现象:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 select ename from emp;#单独查emp表的ename字段
加限制条件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 select emp.ename,dept.dname from emp,dept where emp.deptno = dept.deptno order by dname;#只有emp中的deptno和dept中的deptno相等时
内连接——等值连接
上述笛卡尔积现象SQL语句是SQL92语法,SQL99语法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 select e.ename,d.dname from emp e join dept d on e.deptno = d.deptno order by dname;
内连接——非等值连接:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #eg:找出每个员工的薪资等级,要求显示员工名、薪资、薪资等级
内连接——自连接:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #查询员工的上级领导、要求显示员工名和对应的领导名
外连接:
查询员工表可以发现员工表中有10、20、30部门:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 select * from emp;
查询部门表发现除了10/20/30部门还有40部门:
1 2 3 4 5 6 7 8 9 select * from dept;
如果希望将除了员工表里有的部门输出外,同时输出员工表中没有的部门,就要用到外连接了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 select e.ename,d.dname from emp e right join dept d on e.deptno = d.deptno;#right表示将join关键字右边的这张表看做主表,主要是为了将这张表的数据全部查询出来,捎带着关联查询左边的表
举一反三一下很容易得出左连接的写法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 select e.ename,d.dname from dept d left join emp e on e.deptno = d.deptno;#记得把join两侧表名换位置
外连接查询结果条数大于等于内连接
同样是上面员工领导的问题,使用外连接,可将显示所有员工的结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 select a.ename as '员工',b.ename as '领导' from emp as a left join emp as b on a.mgr = b.empno;
总结:内连接取交集,外连接取并集
多张表连接:
语法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 SELECT
子查询:
select语句的嵌套
where中的子查询:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 select ename,sal from emp where sal > min(sal);#这句语句是错误的,shiyong max()前未分组
from中的子查询:
注:from后面的子查询可以将子查询的查询结果当做一张临时表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #eg:找出每个岗位的平均工资的薪资等级
联合查询(UNION):
合并查询结果集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 select ename,job from emp where job = 'MANAGER';
注意:union联合查询的两个结果要求列的数目以及数据类型相同
limit:
WEEK2 <!DOCTYPE html>是H5的声明位于文档的最前面,处于标签之前。他是网页必备的组成部分,避免浏览器的怪异模式。
meta标签用于描述一个HTML网页文档的属性,关键词等,eg:<meta charset='UTF-8'>,是单标签
生成<h1>到<h6>快捷键:h$*6
align属性,调整标题摆放位置
<h1 align='left|right|center'>居左,右,中,默认居左</h1>>
段落通过<p>标签定义<p>这是一个段落</p>
<p>这是一个可以换<br>行的标签</p>
<hr/>标签在html页面中创建水平线,<hr color="" width="" size="" aligh="" />
color:颜色
width:长度
size:水平线高度
align:对齐方式,默认居中