解决burpsuite报文Filter中无法对中文字符进行过滤的问题
本文最后更新于:9 个月前
自我放松了好长一段时间,本来想水一水的一篇文章也是咕咕咕到了一个礼拜之后
起因是一个师傅来问我burp的Proxy中,过滤器没法过滤出中文,我心想还有这事
随便访问了下百度,确认有报文响应是包含中文字符”百度”的
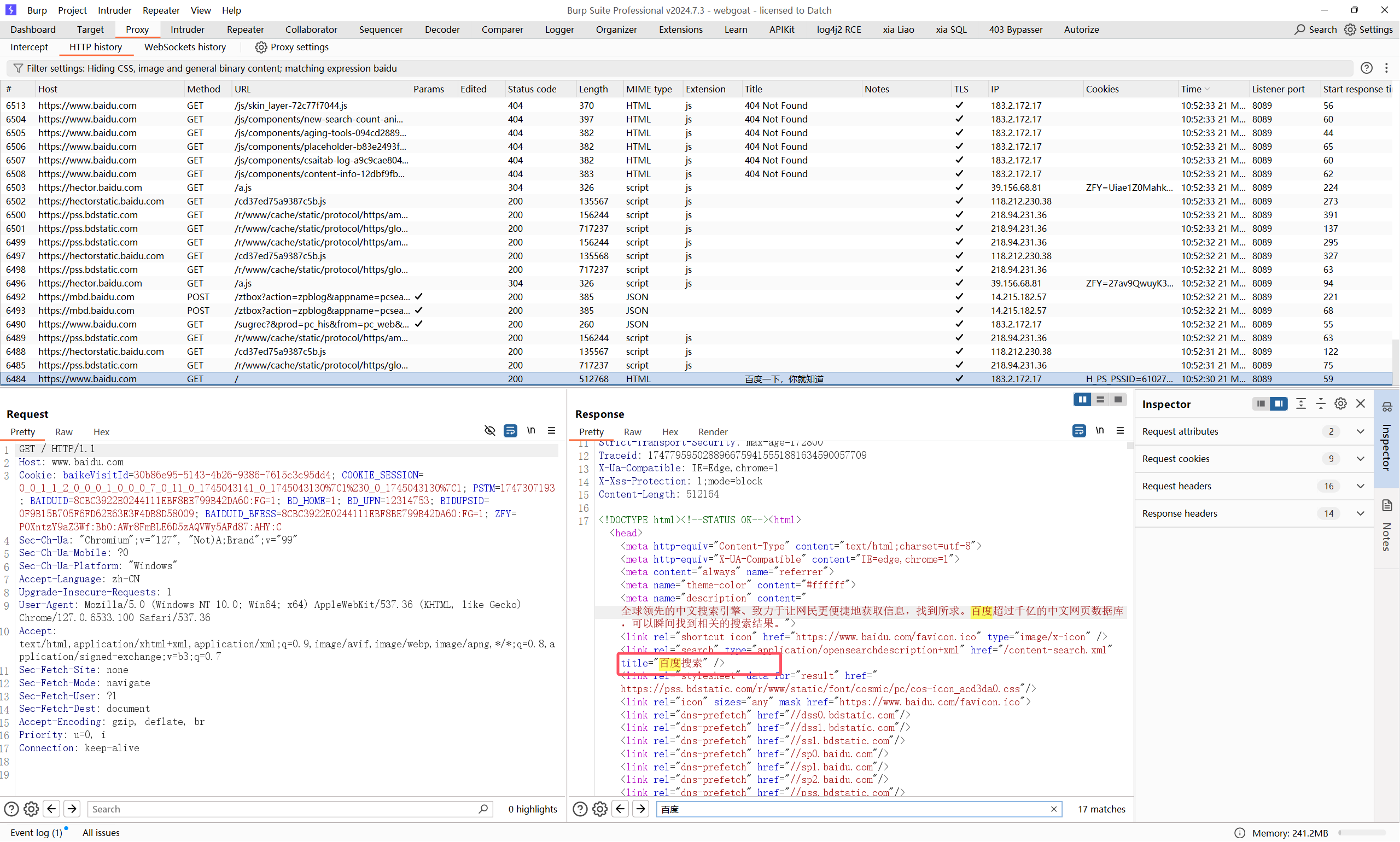
然后按照师傅碰到的情况试了下直接过滤,好家伙,真一个没过滤出来
尝试过修改burp的全局编码,还是没办法,问题大概就是burp的请求和响应实际上都是一个个的数据流,bp在显示请求和响应的时候会根据用户设置的选项来编码,也就是第一张图中我们看到的场景,但是当我们在过滤器中试图以中文字符作为条件进行过滤的时候,它未必按照utf-8进行编码,自然就没办法过滤出合适的选项了
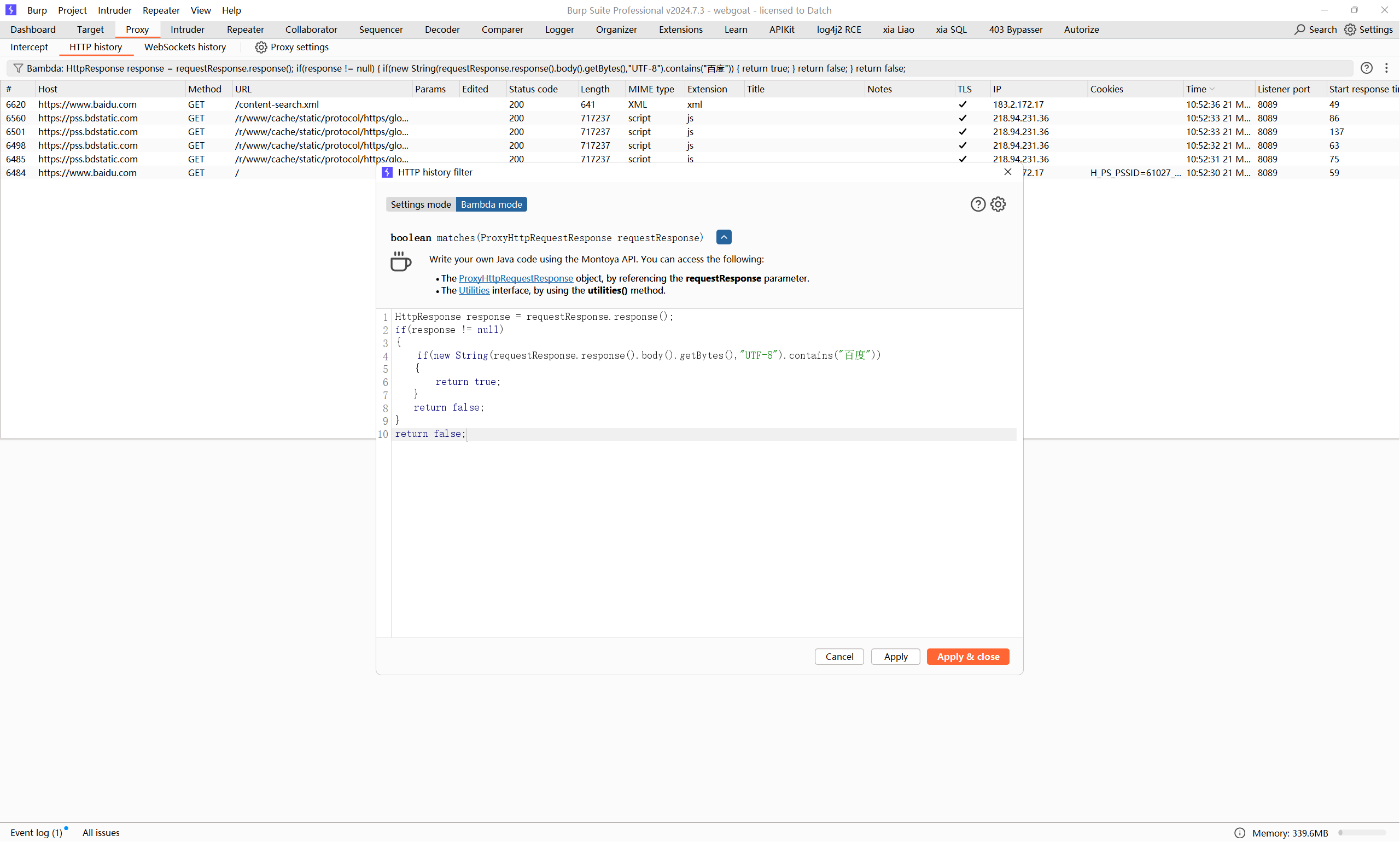
当然burp还给我们提供了一个更强大的处理方式,也就是自己编写Bambda表达式
红框中的部分是一个match()方法的实现,而下面我们正是要去自己定义的方法体
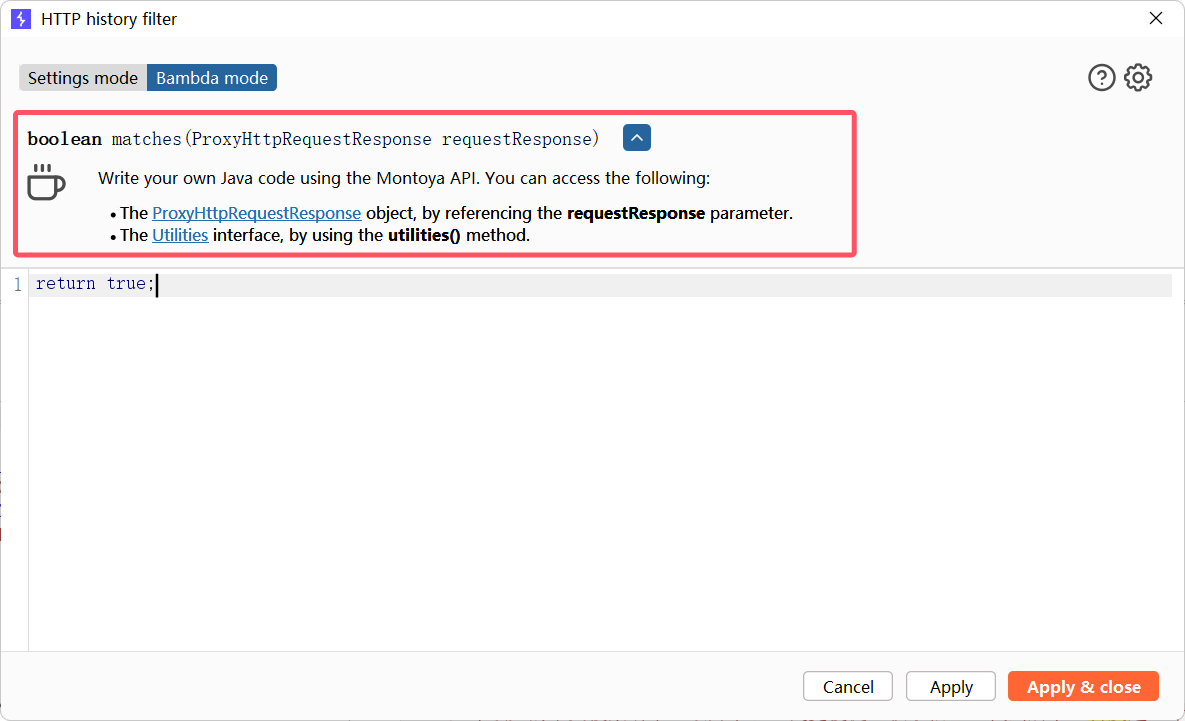
中间出了点小插曲,(干啥前还是要思考思考可能的后果,,只能说这一层我当时也没想到直接就炸膛了)
cpu直接干飞到100%,电脑在轰鸣
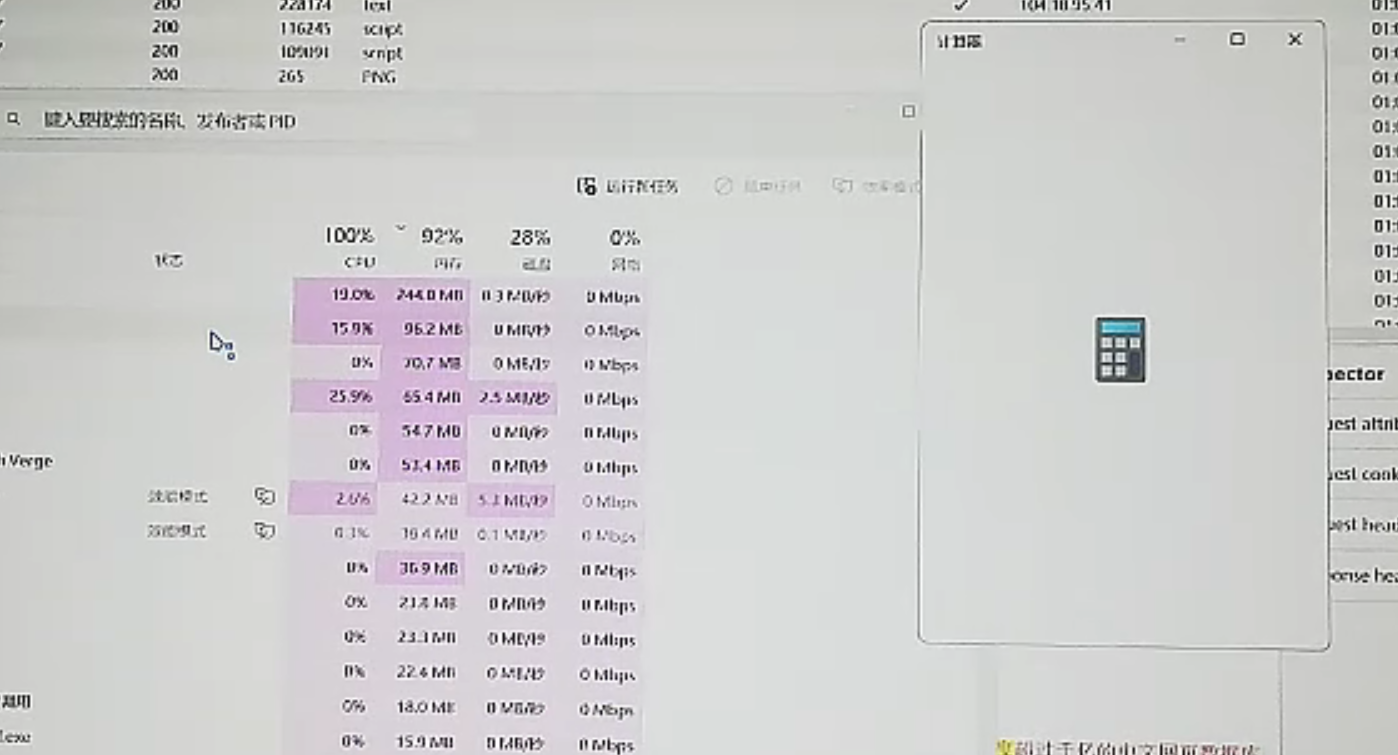
然后
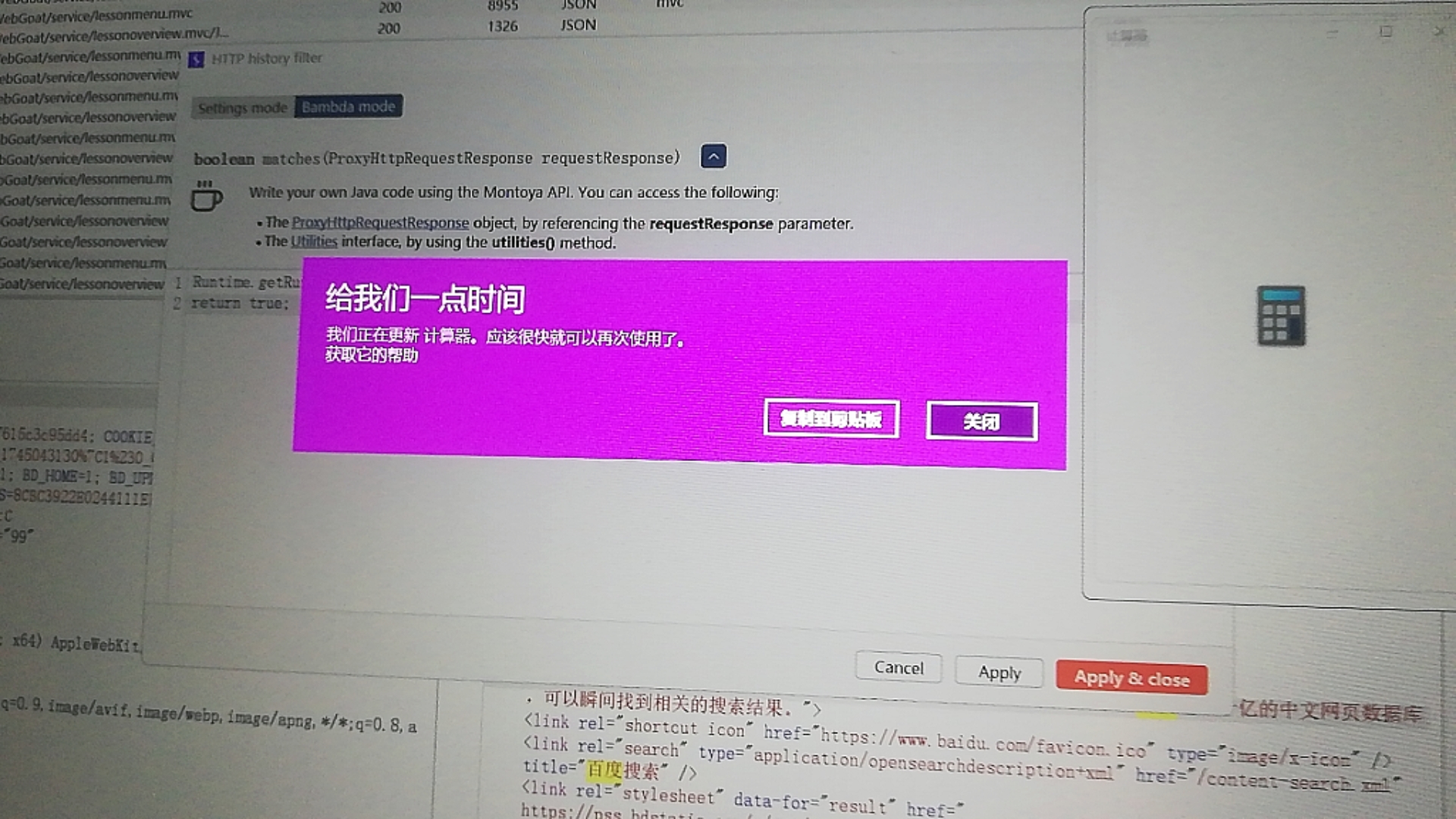
最后啥也干不了,被迫强制重启(还好Typora开了自动保存)
回到上面的话题!!
红框中的部分是一个match()方法的实现,而下面我们正是要去自己定义的方法体
我们希望请求和响应以utf-8的形式解码,并包含字符串”百度”,思路就是获取请求和响应的原始字节流,然后new String(byte[],”utf-8”)就完事了
那么字节流怎么获取呢?
他已经给我们了一个ProxyHttpRequestResponse的对象作为参数传入了
前面编写过burp插件,所以还是有一定敏感性的,碰到这种情况直接去翻burp提供的接口文档
ProxyHttpRequestResponse给出的接口中,提供了两个方法response()和request()用于分别获取请求和响应
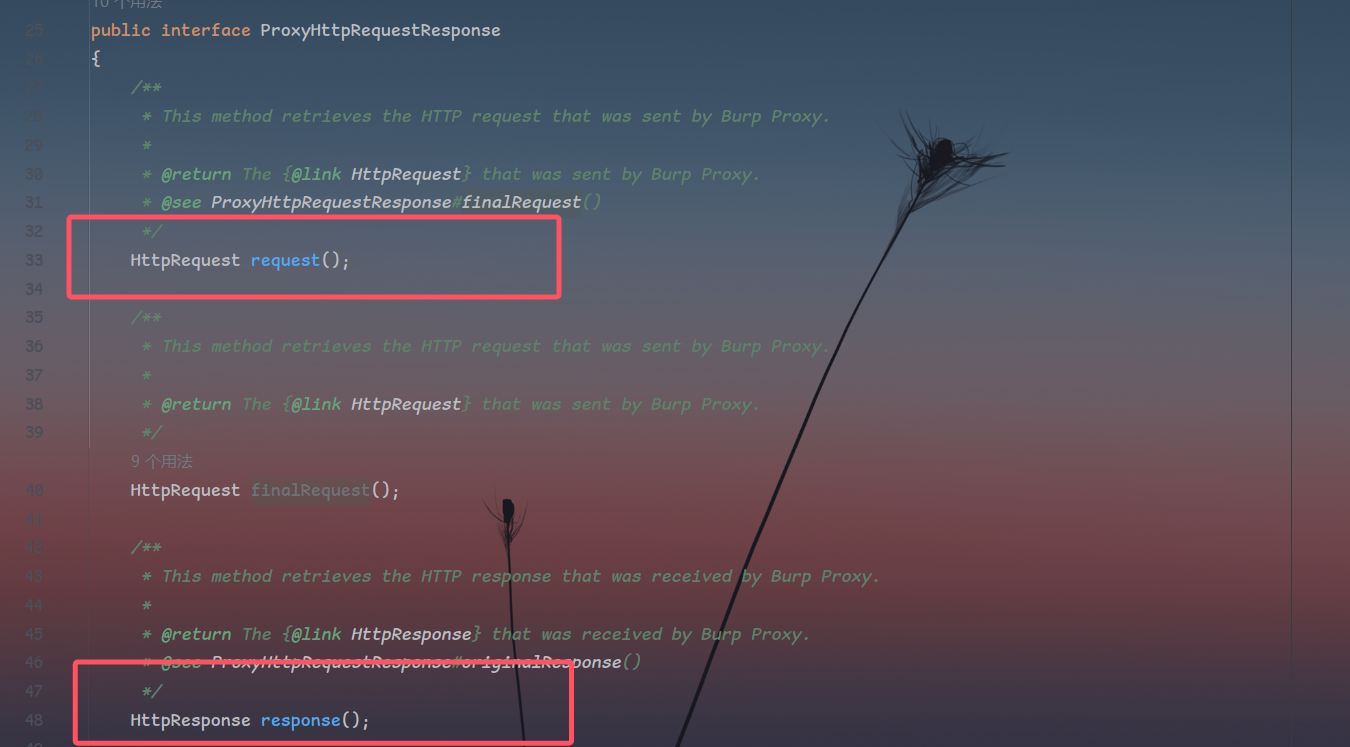
以响应为例,我们跟进HttpResponse,也就是response()接口的返回类型
看到这么个方法,返回响应体并转为字符串
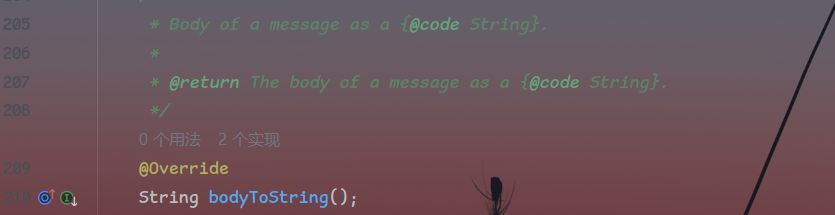
抱着侥幸心理试了下,不出所料
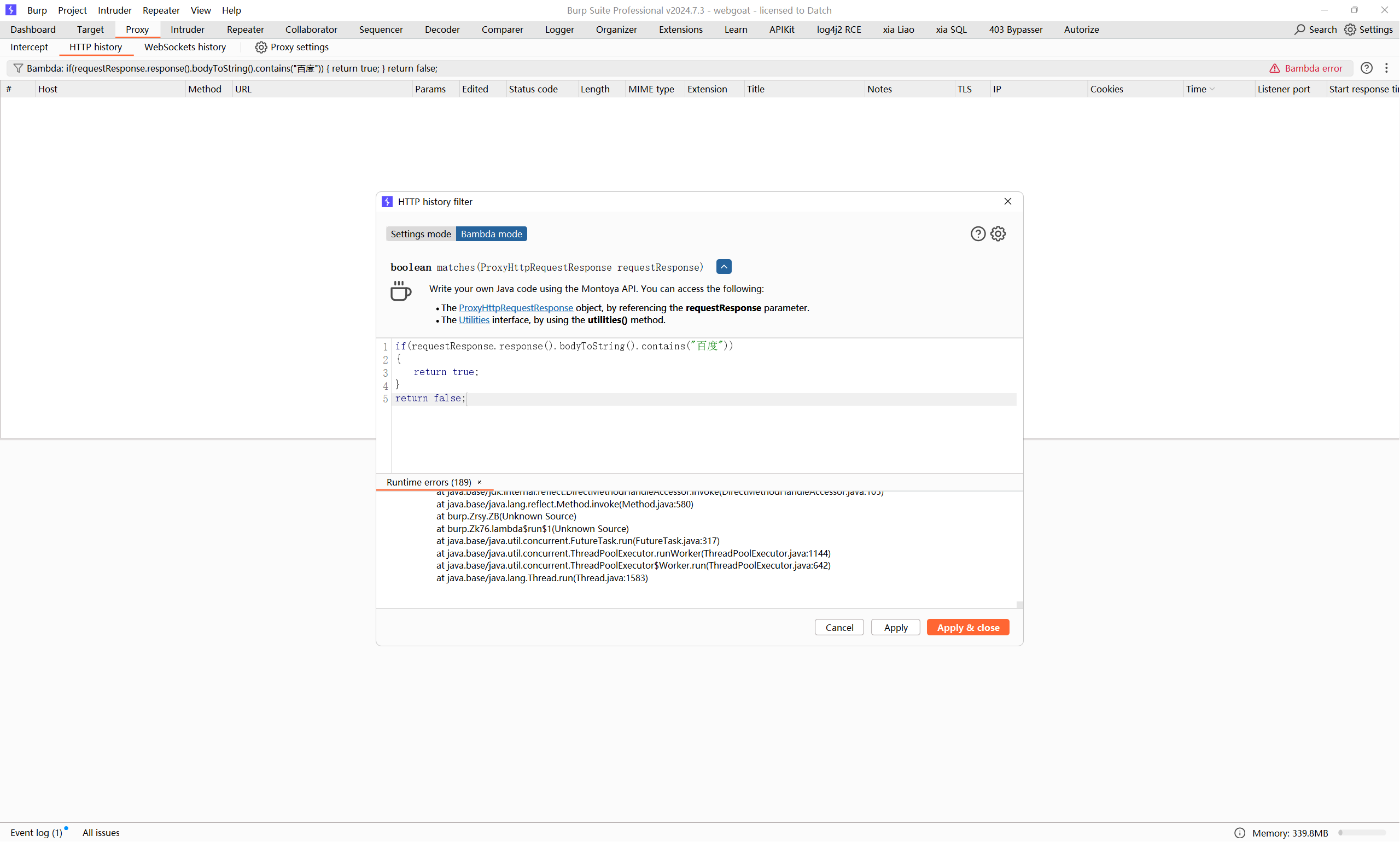
还是老老实实找字节流吧,很快就找到了另一个方法,返回了ByteArray类型的body()接口,虽然ByteArray不是原生的字节类型,但是大概也能猜出个所以然了
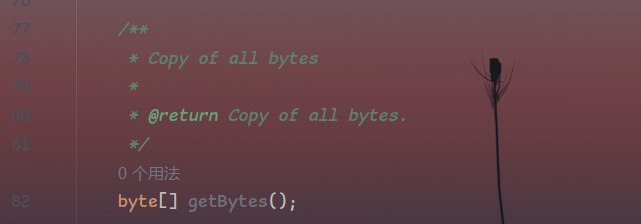
很显然,应该跟进ByteArray

不难找到这么个getByte()方法,正是我们一开始需要的原始字节流信息
简单写了个demo:
1 | |
成功~
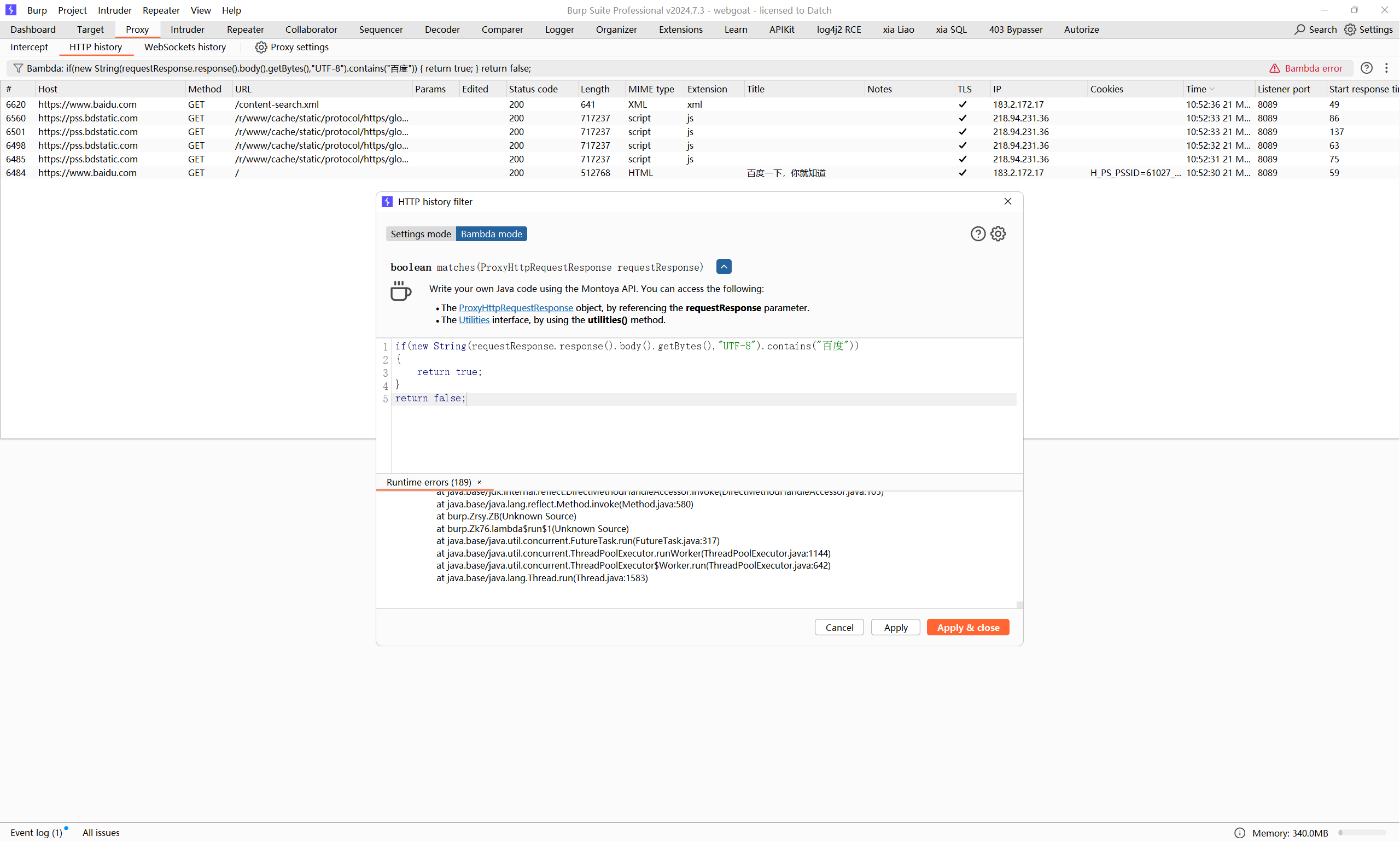
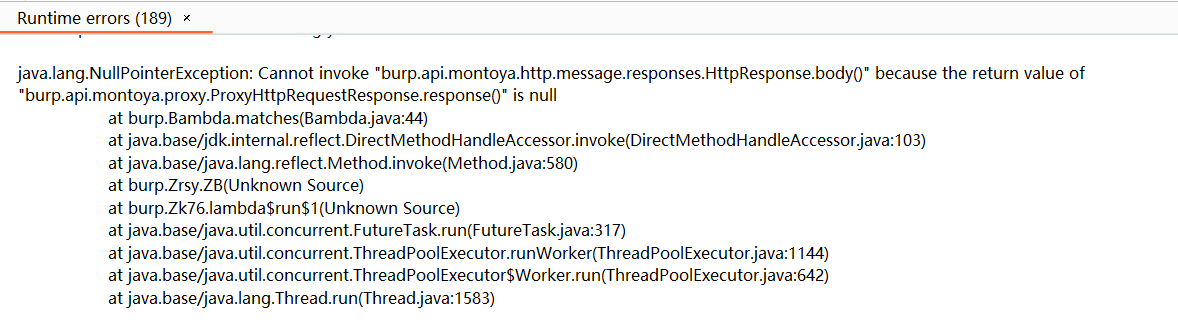
不过还不是很完美,可以看到日志中提示了一些异常
是一个空指针异常,很显然是因为我们的response()返回结果为null,对应的情况就是有一些请求包并没有得到响应
简单做个判断就行
1 | |
最终效果